Cython基础

入门教程
Cython概念
Cython本质上就是具有C数据类型的Python。
除了极少数例外,几乎所有的Python代码都是有效的Cython代码。Cython的编译器会把代码转换成等效于调用Python/C API的C代码。
由于Cython的参数和变量可以背声明为具有C数据类型,因此可以自由地混用操作Python值和C值的代码,而Cython会自动转换需要转换的地方。此外,Python中的引用计数保存和错误检查也是自动的,而且Python的异常处理机制,包括try-except和try-finally同样可行,即使是在操作C数据时。
Cython的第一个程序
Cython可以接受几乎所有有效的Python源文件,因此在Cython的启程之路上最大的拦路虎之一就是如何去编译拓展文件。
首先从标准的Python Hello, World开始:
print("Hello, World")将这段代码保存为helloworld.pyx。现在需要创建一个setup.py,这就像是一个Python的Makefile,因此setup.py应该像这样:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("helloworld.pyx")
)接着使用下面的命令行来建立Cython文件:
python setup.py build_ext --inplace在类Unix系统中,这行命令会在你的本地文件夹中创建一个叫做helloworld*.so的文件。在Windows系统中,它叫helloworld*.pyd。现在运行Python解释器,然后把这个文件当成一个普通的Python模块简单的import它就可以使用了:
import helloworldHello, World恭喜!此时你已经知道如何去创建一个Cython拓展了,但是这个例子会给人一种不知道Cython有何优势的感觉,所以接下来介绍更有现实意义的例子。
Pyximport模块
如果Cython模块不需要任何外部的C库或者特殊的安装方式,那便可以直接使用pyximport模块。该模块由Paul Prescod开发,用来直接使用import来载入*.pyx文件,而不需要在每次更改代码的时候都重新运行一遍setup.py文件。pyximport模块的使用方式如下:
import pyximport; pyximport.install()
import helloworldHello, Worldpyximport模块也支持对普通Python模块的实验性编译,这可以使得在Python导入每个*.pyx和*.py模块上自动运行Cython,包括标准库和被安装的包。Cython在编译大量Python模块的时候也会经常失败,此时import机制将会回溯,转而去载入Python源模块:
import pyximport; pyximport.install(pyimport=True)(注意,这种方式现已不推荐!)
例子:字符串转整数
在之前Python基础中有一个简单的字符串转整数的例子:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))现在可以跟着上面Hello, World的例子照葫芦画瓢。首先将文件拓展名更改为str2int.pyx,接下来创建setup.py文件:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("str2int.pyx"),
)创建拓展的命令与helloworld.pyx的例子相同:
python setup.py build_ext --inplace使用拓展的方式也很简单:
import str2int
str2int.str2int('2021111052')2021111052也可以使用pyximport模块来导入拓展:
import pyximport; pyximport.install()
import str2int
str2int.str2int('2021111052')2021111052Cython特性
下面通过一个小例子来介绍Cython的特性。
# 加载Cython扩展
%load_ext Cython
%%cython
def primes(int nb_primes):
cdef int n, i, len_p
cdef int p[1000]
if nb_primes > 1000:
nb_primes = 1000
len_p = 0 # p中当前元素的数量
n = 2
while len_p < nb_primes:
# 是否是质数?
for i in p[:len_p]:
if n % i == 0: # 存在一个因数则跳过,不是质数
break
else: # 一个因数都没有,是质数
p[len_p] = n
len_p += 1
n += 1
result_as_list = [prime for prime in p[:len_p]]
return result_as_list
primes(10)[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]可以发现,函数的开始部分就像普通的Python函数定义,除了参数nb_primes被声明为int类型,这意味着这个参数被传入时会被转换为C的整数类型(如果转换失败则是TypeError)。
在函数体中,使用了cdef语句来定义一些局部的C变量:
...
cdef int n, i, len_p # 定义一些局部的C变量
cdef int p[1000]
...在处理过程中,结果被保存在一个C数组p中,并且最后被复制到一个Python列表中:
...
p[len_p] = n # 结果被保存在C数组中
...
result_as_list = [prime for prime in p[:len_p]] # 复制到Python列表中
...- 注意,在上述例子中,不能创建太大的数组,因为数组是被分配在C函数调用的栈上的,而这些栈资源是有限的。如果需要更大的数组或者这些数组的长度只有在程序运行时才能被确定,可以使用Cython对C内存进行分配或者使用Numpy数组等等进行提高效率。
在C中声明一个静态数组需要在编译时确定数组的大小,所以程序中需要确保传入的参数不得大于数组的大小,否则会抛出类似C中的段错误:
...
if nb_primes > 1000:
nb_primes = 1000 # 防止传入的参数超过数组大小
...值得注意的是下面这段代码:
...
for i in p[:len_p]:
if n % i == 0:
break
...这段代码使用候选数字依次除以已经找到的每一个质数来判断候选数字数不是质数。因为这里面没有Python对象被引用,循环被整体翻译成了C代码,所以运行速度大幅提高。请注意迭代C数组p的方式:
...
for i in p[:len_p]: # 虽然循环被翻译成C代码,但依然可以像操作Python列表一样使用切片,提高运行效率
...在返回结果之前,需要先将C数组复制到一个Python列表里,因为Python不能读取C数组。Cython可以自动将很多C类型转换为Python类型:
...
result_as_list = [prime for prime in p[:len_p]] # 复制到Python列表中
...请注意,正如Python声明一个Python列表的形式,result_as_list没有被显式声明,因此它会被视为一个Python对象。
至此,Cython的基本用法已经明了,但Cython究竟帮我们节省了多少工作量还是值得探究的。可以在cythonize()中传入参数annotate=True生成一个HTML文件:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("primes.pyx", annotate=True)
)在HTML文件中可以发现,黄色行代表改行与Python进行交互,交互的越多颜色就越深。白色行则表示没有与Python进行交互,该部分代码被完全翻译成C代码。
这些黄色行会操作Python对象、生成异常或是做一些其他更高级的操作,因此都不能被翻译成简单快速的C代码,函数声明和返回使用了Python的解释器所以这些行也是黄色的。
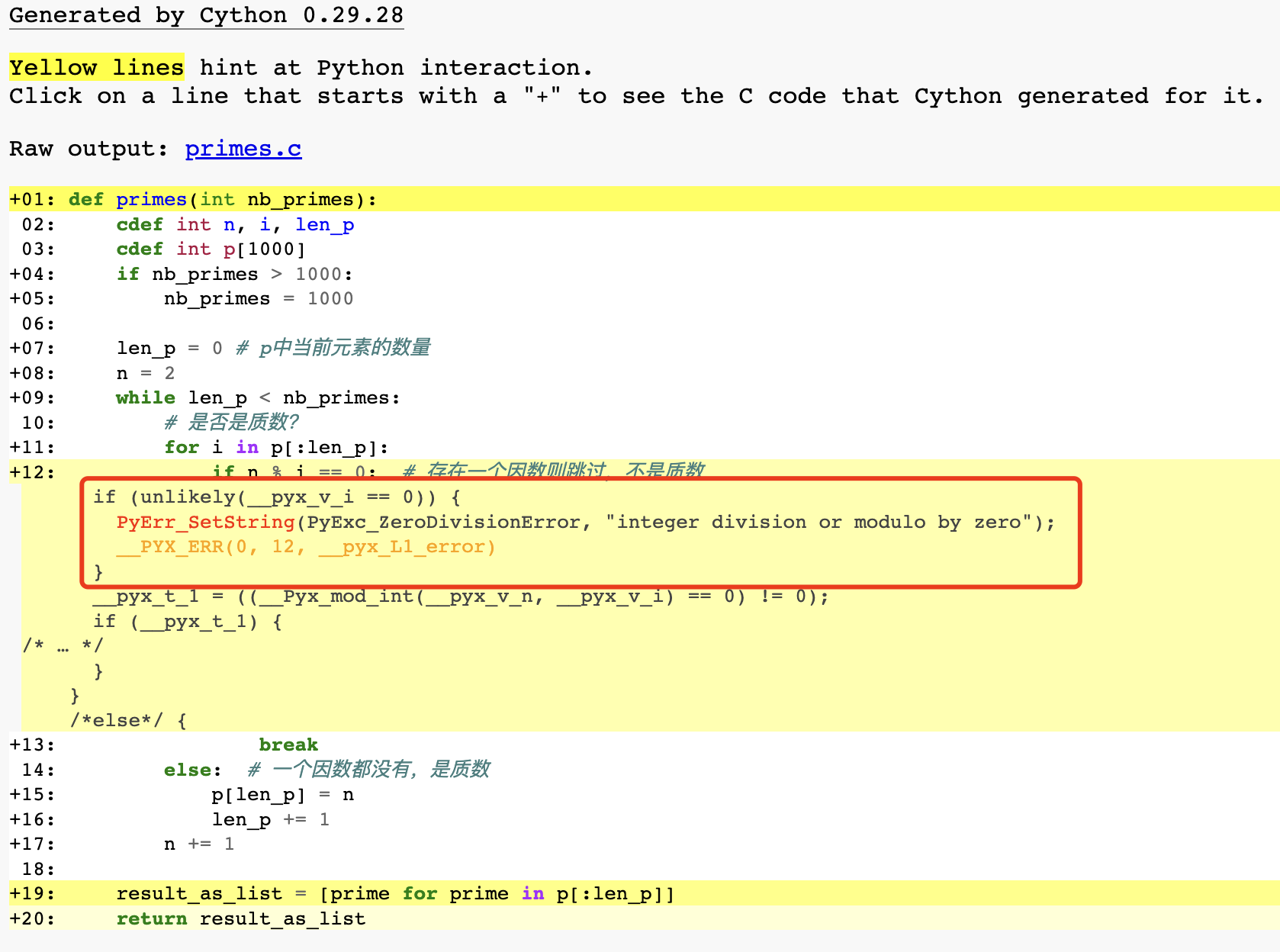
此外,按照逻辑if n % i == 0:这行语句可以直接通过C代码实现,为什么会标黄呢?可以发现Cython在这里默认使用Python在运行时的除法检查。可以使用编译器指令cdivision=True禁止这种检查。
性能对比
针对上述primes的例子,下面是一个Python版的相同程序:
def primes_python(nb_primes):
p = []
n = 2
while len(p) < nb_primes:
# 是否是质数?
for i in p:
if n % i == 0:
break
# 如果循环中未发生break
else:
p.append(n)
n += 1
return p%%time
cython = primes(1000)CPU times: user 1.62 ms, sys: 0 ns, total: 1.62 ms
Wall time: 1.62 ms%%time
python = primes_python(1000)CPU times: user 24.6 ms, sys: 0 ns, total: 24.6 ms
Wall time: 23.7 mscython == pythonTrue从上述对比中可以发现,Cython的速度几乎数十倍优于Python。很明显C比Python对于CPU的缓存的支持性更好,Python中一切皆对象,均以字典的形式存在,对于CPU缓存是不友好的。一般来说Cython的速度会是Python的2倍到1000倍之间,具体取决于调用Python解释器的次数。
C++版本的Primes
上面的Cython调用的都是C API,当然Cython也可以调用C++(部分C++的标准库可以在Cython代码中被直接导入)。下面是使用C++标准库中vector后的primes函数:
# distutils: language=c++
from libcpp.vector cimport vector
def primes(unsigned int nb_primes):
cdef int n, i
cdef vector[int] p
p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
n = 2
while p.size() < nb_primes: # vector的size()和len()类似
for i in p:
if n % i == 0:
break
else:
p.push_back(n) # push_back is similar to append()
n += 1
return p # 在转换到Python对象时,vector可以被自动转换为Python列表 第一行# distutils: language=c++是编译器指令,告诉Cython把代码编译成C++,这样就可以使用C++的特性和C++标准库(注意,pyximport无法把Cython代码编译成C++,需要使用setup.py)。
可以看到,C++的vector API和Python的列表API非常相似,在Cython中经常可以做替换。
更多在Cython中使用C++的细节请参阅在Cython中使用C++。
更多Cython语言基础请参阅语言基础。
中文Cython文档请参阅Cython中文文档。