NVIDIA DALI Tutorials

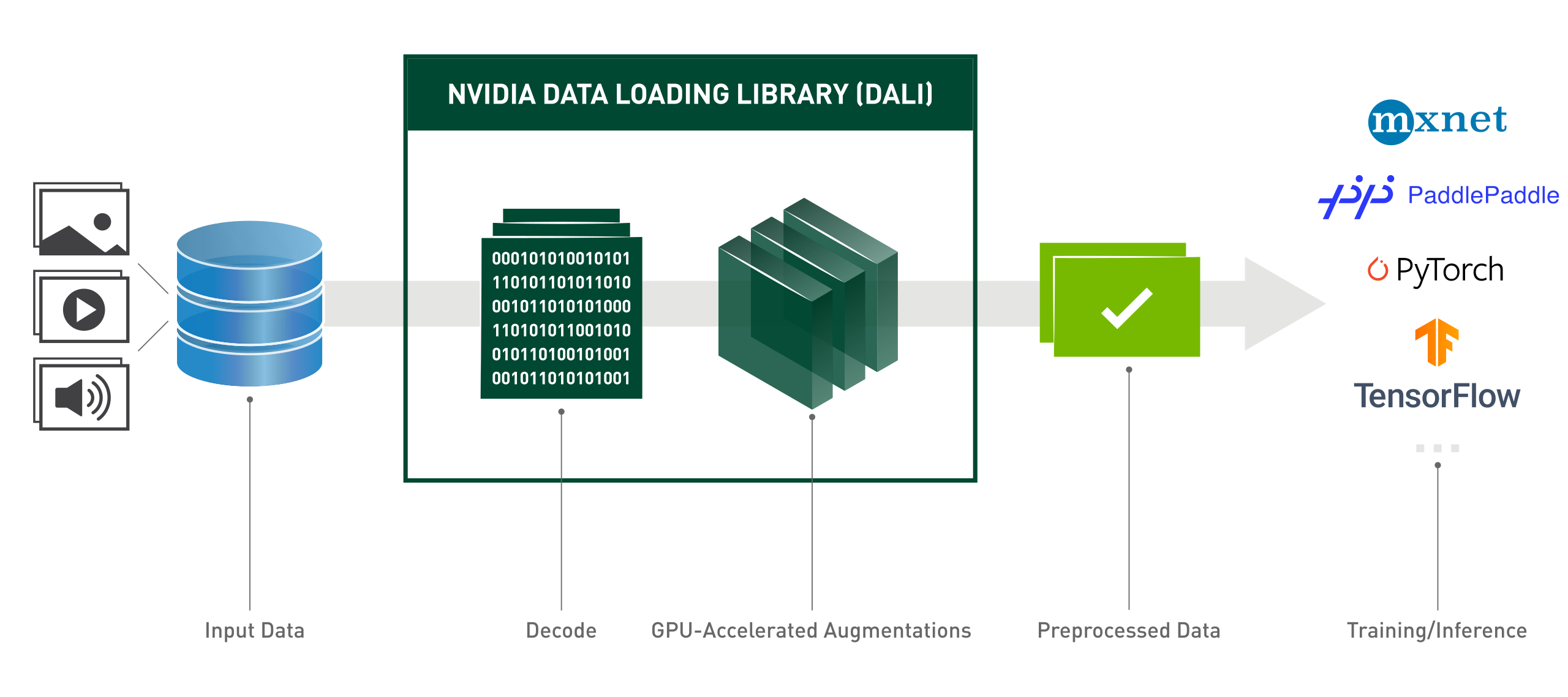
First Encounter
The origin of this matter dates back to when I read a paper a long time ago. The core of the paper was to discuss the role of pre-training strategies in low-level vision tasks. Since it’s about pre-training strategies, inevitably, a larger dataset is required. The reason pre-training has been rarely applied in low-level vision tasks in recent years is mainly due to the lack of large-scale datasets. This paper focuses on three tasks in low-level vision tasks: SR (Super-Resolution), DeRain (Rain Removal), and DeNoise (Noise Reduction). The authors used images from ImageNet as the base images and obtained low-resolution images for the SR task using bicubic interpolation, while rain streaks and Gaussian noise were directly added to the clean base images for the DeRain and DeNoise tasks.
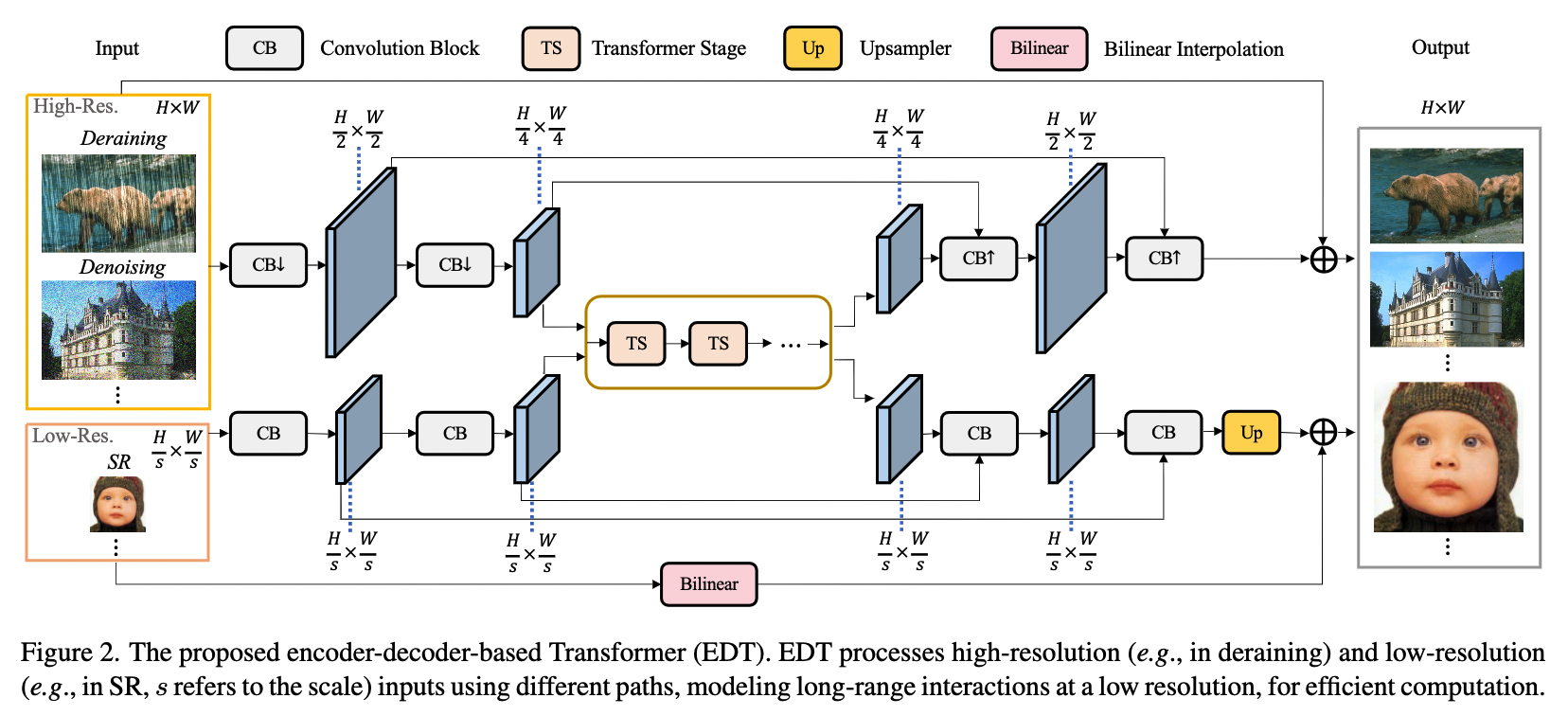
However, the paper overlooked a very important issue in low-level vision, namely the Low-light Image Enhancement task. I think the main problem is that paired image datasets used in low-light enhancement tasks are difficult to obtain, especially using ImageNet, which is even more challenging. First, low-light environments are complex, not simply achieved by reducing the brightness of an image. Images taken in low-light environments often have areas that are dark and areas that are bright; second, images captured in low-light environments often come with various complex noises, and simply adding noise to the images may not be realistic. I recently overcame these two problems and successfully selected some appropriate images from five datasets: ImageNet, VOC, COCO, IAPR, and StreetScenes, to construct a large-scale paired dark-light image dataset, which contains a total of 153,856 pairs of dark/normal light images (I won’t go into detail about how the dataset was constructed today, I will explain it in detail after the paper is published). We know that PyTorch provides the torch.utils.data.Dataset(*args, **kwds) and torch.utils.data.DataLoader(dataset, ...)=classes to implement dataset construction and data loading, but both classes operate on the CPU. However, our pre-training dataset has reached 153,856*2 images, and loading them with the CPU is really too slow. This might lead to the model waiting for data input during subsequent training, that is, the model has already trained a batch of data, but the next batch of data is still loading and has not been promptly delivered to the model, causing a significant drop in GPU utilization. That is to say, it not only reduces the speed of model training but also fails to fully utilize the performance of hardware such as graphics cards, which is a very low-cost-effective thing. Here’s an 🌰 (example):
import os
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader, random_split
torch.__version__
DATA_DIR = "/home/jensen/workspace/DATASETS/SYNTHETIC_DATA"
BATCH_SIZE = 128
IMAGE_SIZE = 192
syn_trans = transforms.Compose([
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE)),
transforms.ToTensor(),
])
class Syn_Dataset(nn.Module):
def __init__(self, low_path, high_path, transforms=None):
self.low_path = low_path
self.high_path = high_path
self.transforms = transforms
def __getitem__(self, idx):
low_files = os.listdir(self.low_path)
high_files = os.listdir(self.high_path)
low_image = Image.open(os.path.join(self.low_path, low_files[idx]))
high_image = Image.open(os.path.join(self.low_path, high_files[idx]))
if self.transforms:
low_image = self.transforms(low_image)
high_image = self.transforms(high_image)
return low_image, high_image
def __len__(self):
return len(os.listdir(self.low_path))
dataset = Syn_Dataset(low_path=os.path.join(DATA_DIR, "low"), high_path=os.path.join(DATA_DIR, "low"), transforms=syn_trans)
train_data, val_data = random_split(dataset, (152000, 1856))
val_loader = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
%%time
for idx, data in enumerate(val_loader):
X, Y = data
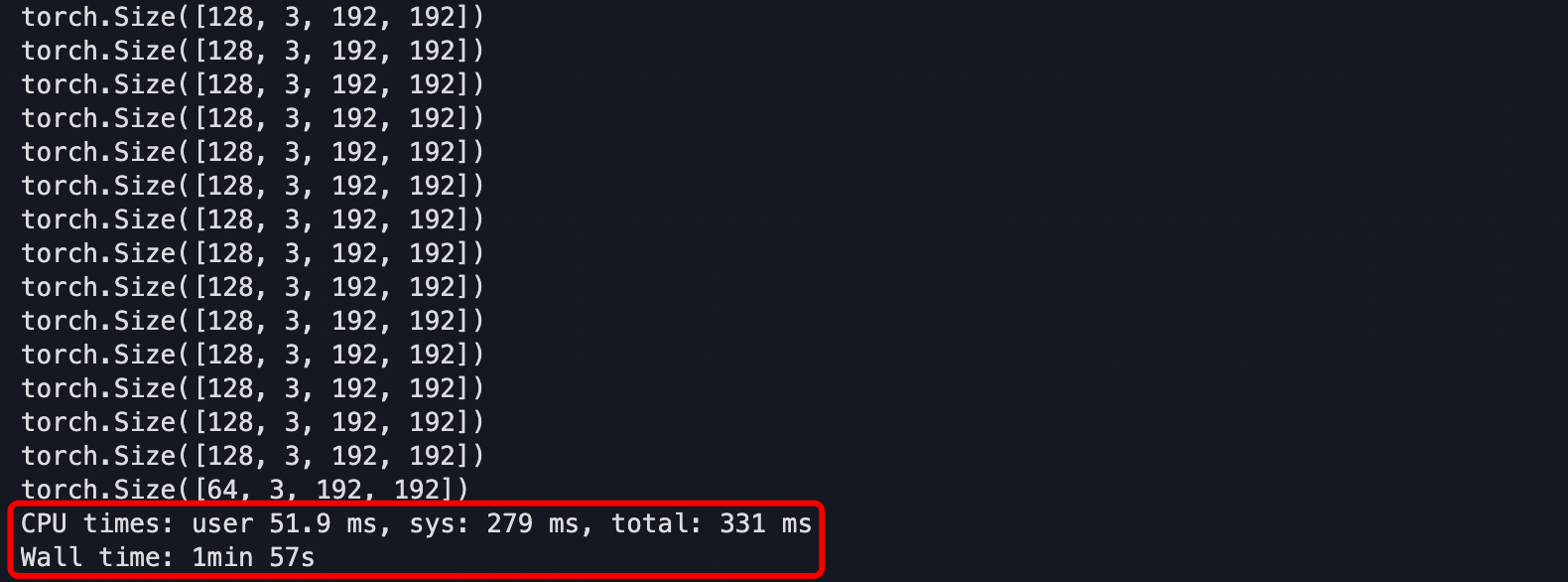
print(X.shape)In the example above, the built-in DataLoader class in PyTorch is used to iterate through the val_dataset with batch_size = 128, and the size of each batch is printed. Using the %%time magic command in jupyter to calculate the time spent on a complete iteration, it can be seen from the figure below that it took nearly two minutes to complete one iteration.
Next, let’s give another 🌰:
from torchvision import models
model = models.alexnet(pretrained=False).cuda()
criterion = nn.CrossEntropyLoss()
for idx, data in enumerate(val_loader):
X, Y = data
output = model(X.cuda())
loss = criterion(out.cpu(), torch.empty(out.shape[0], dtype=torch.long).random_(1000))
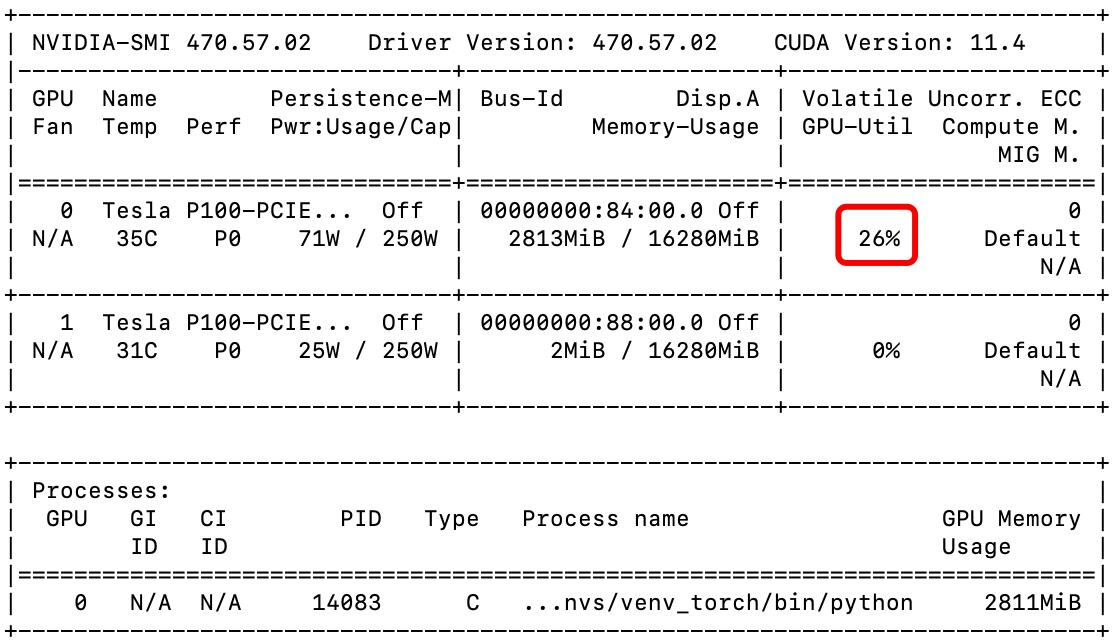
loss.backward()The example above simulates feeding data into AlexNet for processing. From the figure below, it can be observed that the GPU utilization is very low (most of the time at 0%). The main reason is that the model processes data faster than the data loading time, meaning that the model often has to wait for the DataLoader to pass the new batch of data over, resulting in the GPU utilization being low or even idle most of the time, severely slowing down the efficiency of model training.
If the data scale is small, this amount of time might not matter, but my data scale is on the level of hundreds of thousands, every minute and second can be said to be very precious. Therefore, I found a very nice acceleration tool: NVIDIA DALI library.
Using NVIDIA DALI in a Single GPU Environment
(For the specific usage of NVIDIA DALI, please refer to the official documentation)
Installation
First, you need to determine your cuda version. You can enter nvcc -V in the command line to check, as shown below, the cuda version is 10.2.
Then enter pip install nvidia-pyindex && pip install nvidia-dali-cuda102 in the command line, please note, the cuda102 exactly corresponds to the cuda version 10.2 mentioned above.
Using in a Single GPU Environment
Using in a single GPU environment means that only one card is used during the training process, which is the simplest form. You can define the iteration method of the data, the data Pipeline, and the loading method by yourself. For detailed details, please see the code:
import os
import torch
import numpy as np
from random import shuffle
import nvidia.dali.fn as fn
import nvidia.dali.types as types
from torch.utils.data import random_split
from nvidia.dali.pipeline import Pipeline
from nvidia.dali.plugin.pytorch import DALIGenericIterator, LastBatchPolicy
torch.__version__
class ExternalInputIterator(object):
def __init__(self, batch_size, files, data_dir):
self.low_dir = os.path.join(data_dir, 'low')
self.high_dir = os.path.join(data_dir, 'high')
self.batch_size = batch_size
self.files = list(files)
shuffle(self.files)
def __len__(self):
return len(self.files)
def __iter__(self):
self.i = 0
self.n = len(self.files)
return self
def __next__(self):
if self.i >= self.n:
self.__iter__()
raise StopIteration
low = []
high = []
leave_num = self.n - self.i
current_batch_size = min(self.batch_size, leave_num)
for _ in range(current_batch_size):
filename = self.files[self.i]
l = open(os.path.join(self.low_dir, filename), 'rb')
h = open(os.path.join(self.high_dir, filename), 'rb')
low.append(np.frombuffer(l.read(), dtype=np.uint8))
high.append(np.frombuffer(h.read(), dtype=np.uint8))
self.i += 1
return (low, high)
next = __next__
len = __len__
class ExternalSourcePipeline(Pipeline):
def __init__(self, data_iterator, batch_size, num_threads, device_id, img_size):
super(ExternalSourcePipeline, self).__init__(batch_size, num_threads, device_id, exec_async=False, exec_pipelined=False)
self.img_size = img_size
self.batch = batch_size
self.data_iterator = data_iterator
self.lows, self.highs = fn.external_source(source=self.data_iterator, num_outputs=2, dtype=types.UINT8)
def __len__(self):
length = len(self.data_iterator)
return (length // self.batch + 1) if (length % self.batch != 0) else (length // self.batch)
def define_graph(self):
low_decode = fn.decoders.image(self.lows, device="mixed")
high_decode = fn.decoders.image(self.highs, device="mixed")
low_resize = fn.resize(low_decode, device="gpu", resize_x=self.img_size, resize_y=self.img_size, interp_type=types.INTERP_TRIANGULAR)
high_resize = fn.resize(high_decode, device="gpu", resize_x=self.img_size, resize_y=self.img_size, interp_type=types.INTERP_TRIANGULAR)
self.low = fn.transpose(low_resize, perm=[2, 0, 1]) / 255.0
self.high = fn.transpose(high_resize, perm=[2, 0, 1]) / 255.0
return (self.low, self.high)
def iter_setup(self):
self.set_outputs(self.low, self.high)
class CustomDALIGenericIterator(DALIGenericIterator):
def __init__(self, pipelines, **kwargs):
output_maps = ['lows', 'highs']
if not isinstance(pipelines, list):
pipelines = [pipelines]
super(CustomDALIGenericIterator, self).__init__(pipelines, output_maps, **kwargs)
self.pipelines = pipelines # devices > 1 ==> pipelines > 1
def __next__(self):
batch = super(CustomDALIGenericIterator, self).__next__()
return self.parse_batch(batch)
def __len__(self):
lengths = [len(i) for i in self.pipelines]
return sum(lengths)
def parse_batch(self, batch):
lows, highs = batch[0]['lows'], batch[0]['highs']
return lows, highs
DATA_DIR = "/home/jensen/workspace/SYNTHESIS_DATA"
BATCH_SIZE = 128
IMAGE_SIZE = 192
files = os.listdir(os.path.join(DATA_DIR, 'low'))
train_files, val_files = random_split(files, (152000, 1856))
val_iter = ExternalInputIterator(batch_size=BATCH_SIZE, files=val_files, data_dir=DATA_DIR)
val_pipe = ExternalSourcePipeline(val_iter, batch_size=BATCH_SIZE, num_threads=4, device_id=0, img_size=IMAGE_SIZE)
val_loader = CustomDALIGenericIterator(val_pipe)
%%time
for idx, data in enumerate(val_loader):
X, Y = data
print(X.shape)The example above uses NVIDIA DALI to customize the data iteration and loading method. Also using the %%time magic function in jupyter to calculate the time spent on a complete iteration, as shown in the figure below, the whole process took less than 3 seconds.

Additionally, simulating feeding data into AlexNet for processing, the GPU utilization can also remain stable at over 85%, indicating that the GPU’s performance is fully utilized.
Using NVIDIA DALI in a Multi-GPU Environment
The multi-GPU environment mentioned in this article refers to single-machine multi-GPU environments, that is, distributed training on multiple GPUs of one machine. However, the situation of multi-machine multi-GPU is not within the scope of this article’s discussion, and I indeed have not used this training method. The usage in a multi-GPU environment can also refer to the official documentation. Let’s directly go to my example:
import os
import nvidia.dali.fn as fn
import nvidia.dali.types as types
from torch.utils.data import random_split
from nvidia.dali.pipeline import Pipeline
from nvidia.dali.plugin.pytorch import DALIGenericIterator, LastBatchPolicy
class SyntheicDataPipeline(Pipeline):
"""
An extended Pipeline class based on the Nvidia DALI library for low-light image enhancement.
The effect of the Pipeline class is somewhat similar to the Dataset class in Pytorch and
the transforms function in torchvision. Mainly is to carry on some simple preprocessing to the input data.
Args:
batch_size (int): batch_size.
data_dir (str): the folder path of the paired image. (excluding the 'low' and' high' folders)
files (list): A list of paired image filenames.
image_size (int | tuple): image size after resize operation. Default: 192
num_threads (int): number of CPU threads used by the pipeline. Default: 2
device_id (int): id of GPU used by the pipeline. Default: 0
seed (int): seed used for random number generation. Default: -1
shard_id (int): index of the shard to read. Default: 0
num_shards (int): partitions the data into the specified number of parts (shards). Default: 1
random_shuffle (bool): determines whether to randomly shuffle data. Default: True
Examples:
When you have a GPU, device_id and shard_id should be set to 0 and num_shards should be set to 1.
When you have four GPU, the value range for device_id and shard_id is [0-3] (device_id and shard_id
values are usually the same), and num_shards should be set to 4.
For details, please refer to the official DALI documentation: https://docs.nvidia.com/deeplearning/dali/user-guide/docs/
or my blog (which will be updated in the near future): https://jensen.dlab.ac.cn/ .
"""
def __init__(self, batch_size, data_dir, files,
image_size=192, num_threads=-1, device_id=0, seed=-1,
shard_id=0, num_shards=1, random_shuffle=True, **kwargs):
super(SyntheicDataPipeline, self).__init__(batch_size=batch_size, num_threads=num_threads,
device_id=device_id, seed=seed, **kwargs)
self.types = ['low', 'high']
self.data_dir = [os.path.join(data_dir, name) for name in self.types]
self.files = list(files)
self.image_size = image_size
self.shard_id = shard_id
self.num_shards = num_shards
self.random_shuffle = random_shuffle
def define_graph(self):
low_inputs, _ = fn.readers.file(file_root=self.data_dir[0], files=self.files, seed=1234,
shard_id=self.shard_id, num_shards=self.num_shards,
random_shuffle=self.random_shuffle, pad_last_batch=True,
name="main_reader")
high_inputs, _ = fn.readers.file(file_root=self.data_dir[1], files=self.files, seed=1234,
shard_id=self.shard_id, num_shards=self.num_shards,
random_shuffle=self.random_shuffle, pad_last_batch=True)
inputs = {'low': low_inputs, 'high': high_inputs}
images = {x: fn.decoders.image(inputs[x], device="mixed") for x in self.types}
resizes = {x: fn.resize(images[x], device="gpu", resize_x=self.image_size,
resize_y=self.image_size, interp_type=types.INTERP_TRIANGULAR)
for x in self.types}
self.tensors = {x: fn.transpose(resizes[x], perm=[2, 0, 1]) / 255.0 for x in self.types}
return (self.tensors['low'], self.tensors['high'])
def iter_setup(self):
self.set_outputs(self.tensors['low'], self.tensors['high'])
class SyntheicDataIterator(DALIGenericIterator):
"""
An extended Iterator class based on the Nvidia DALI library for low-light image enhancement.
The effect of the Iterator class is somewhat similar to the Dataloader class in Pytorch.
Args:
pipelines (nvidia.dali.Pipeline): pipelines.
reader_name (str): name of the reader which will be queried to the shard size,
number of shards and all other properties necessary to count
properly the number of relevant and padded samples that iterator
needs to deal with.
last_batch_policy (int): strategy for processing the last batch data. (especially if the
size of the last batch data is smaller than batch_size)
output_map (list): list of strings which maps consecutive outputs of DALI pipelines to user specified name.
Example:
loader = SyntheicDataIterator(...)
for idx, data in enumerate(loader):
low, high = data
...
For details, please refer to the official DALI documentation: https://docs.nvidia.com/deeplearning/dali/user-guide/docs/
or my blog (which will be updated in the near future): https://jensen.dlab.ac.cn/ .
"""
def __init__(self, pipelines, reader_name, last_batch_policy,
output_map=['low', 'high'], **kwargs):
super(SyntheicDataIterator, self).__init__(pipelines=pipelines, output_map=output_map,
reader_name=reader_name, last_batch_policy=last_batch_policy,
**kwargs)
def _parse_data(self, data):
low_data, high_data = data[0]['low'], data[0]['high']
return low_data, high_data
def __next__(self):
data = super(SyntheicDataIterator, self).__next__()
return self._parse_data(data)
def __len__(self):
return super(SyntheicDataIterator, self).__len__()
DATA_DIR = "/home/jensen/workspace/SYNTHESIS_DATA"
BATCH_SIZE = 128
IMAGE_SIZE = 192
files = os.listdir(os.path.join(DATA_DIR, 'low'))
train_files, val_files = random_split(files, (152000, 1856))
pipe = SyntheicDataPipeline(batch_size=BATCH_SIZE, num_threads=4, device_id=0,
seed=1234, data_dir=DATA_DIR, files=val_files,
image_size=IMAGE_SIZE, shard_id=0, num_shards=1)
val_loader = SyntheicDataIterator(pipe, reader_name="main_reader", auto_reset=True,
last_batch_policy=LastBatchPolicy.PARTIAL)
for idx, data in enumerate(val_loader):
X, Y = data
print(X.shape)The example above is actually a single-machine single-GPU environment, but with a slight modification, it can be turned into a single-machine multi-GPU setup. That is, by slightly modifying the device_id, shard_id, and num_shards parameters in the SyntheticDataPipeline class. device_id is self-explanatory. For example, if a machine has four GPUs, then device_id would be 0, 1, 2, 3. If the computation is performed on the second GPU, then device_id is 2. Furthermore, shard_id generally matches device_id, indicating which shard it is (the essence of distributed training is to divide a large batch of data equally to each GPU for parallel computation, so the first GPU should receive the first shard of the divided data). The num_shards parameter is also easy to understand, meaning how many GPUs there are in total. Although it seems simple, there are still three parameters to modify, which seems a bit troublesome. But don’t worry, in reality, these parameters do not need to be manually set. Usually, distributed training requires passing a parameter --nproc_per_node from the command line, which can adaptively complete the modification of the above parameters. In actual training, only the following modifications are needed: device_id=args.local_rank, shard_id=args.local_rank, num_shards=args.world_size.
That’s it for this blog post. The methods mentioned in this article generally apply to various deep learning tasks, although different tasks may have some differences in data reading. But I believe these issues can be resolved by referring to the usage instructions of nvidia.dali.fn in the official documentation. If I have time later, I will introduce how to use the NVIDIA APEX library for distributed training and how to combine the NVIDIA DALI and APEX libraries for use.